实验流程图与关键步骤
点击右侧卡片可查看关键步骤详情
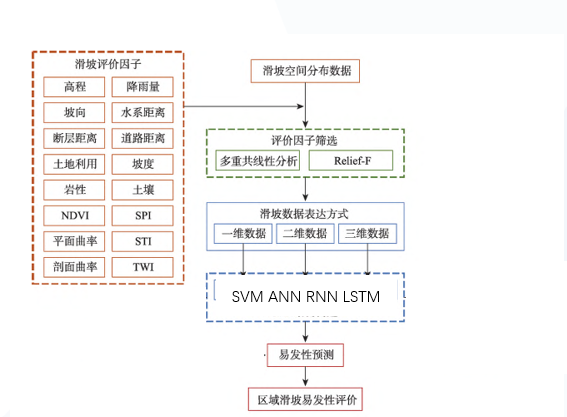
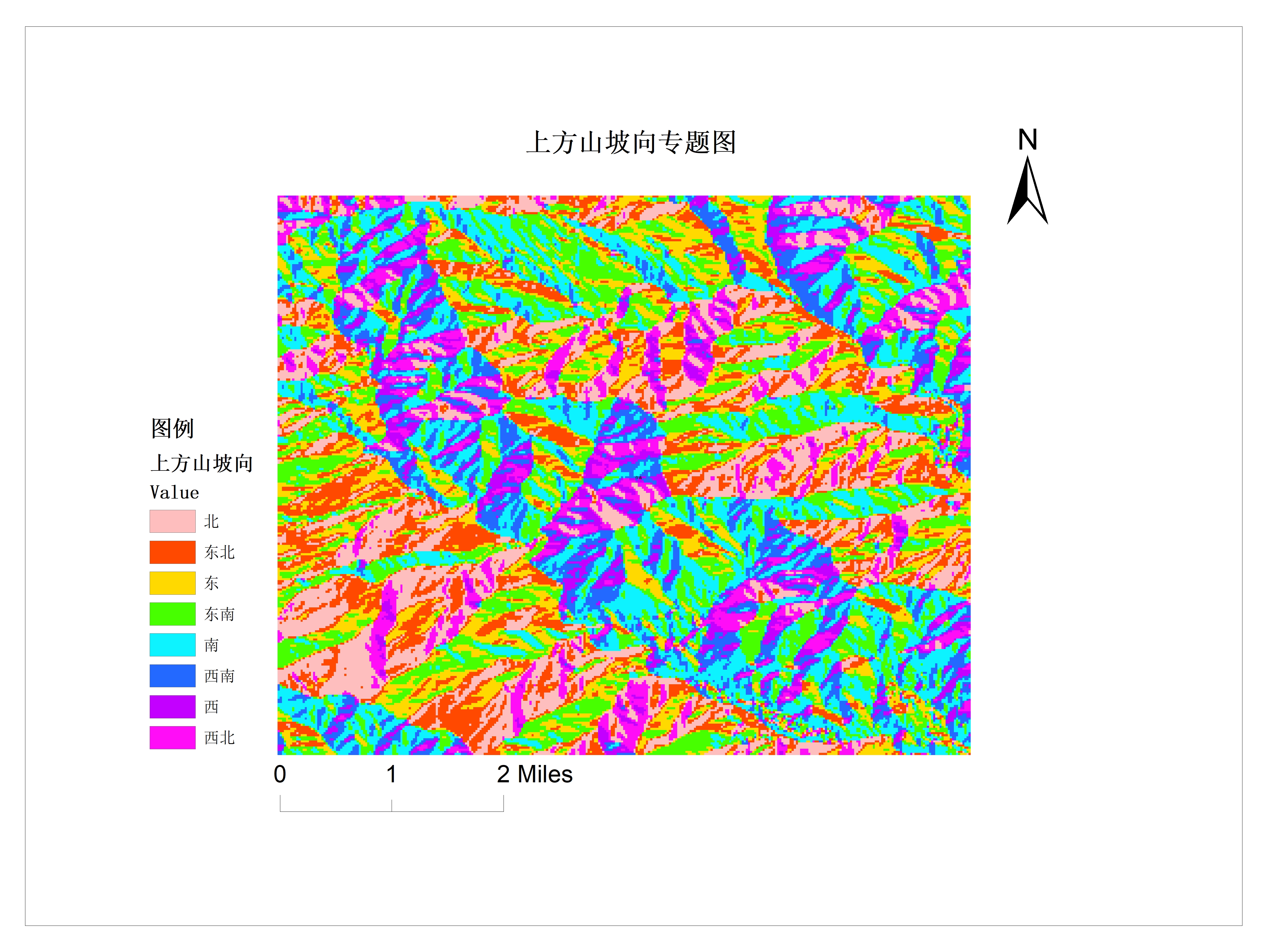
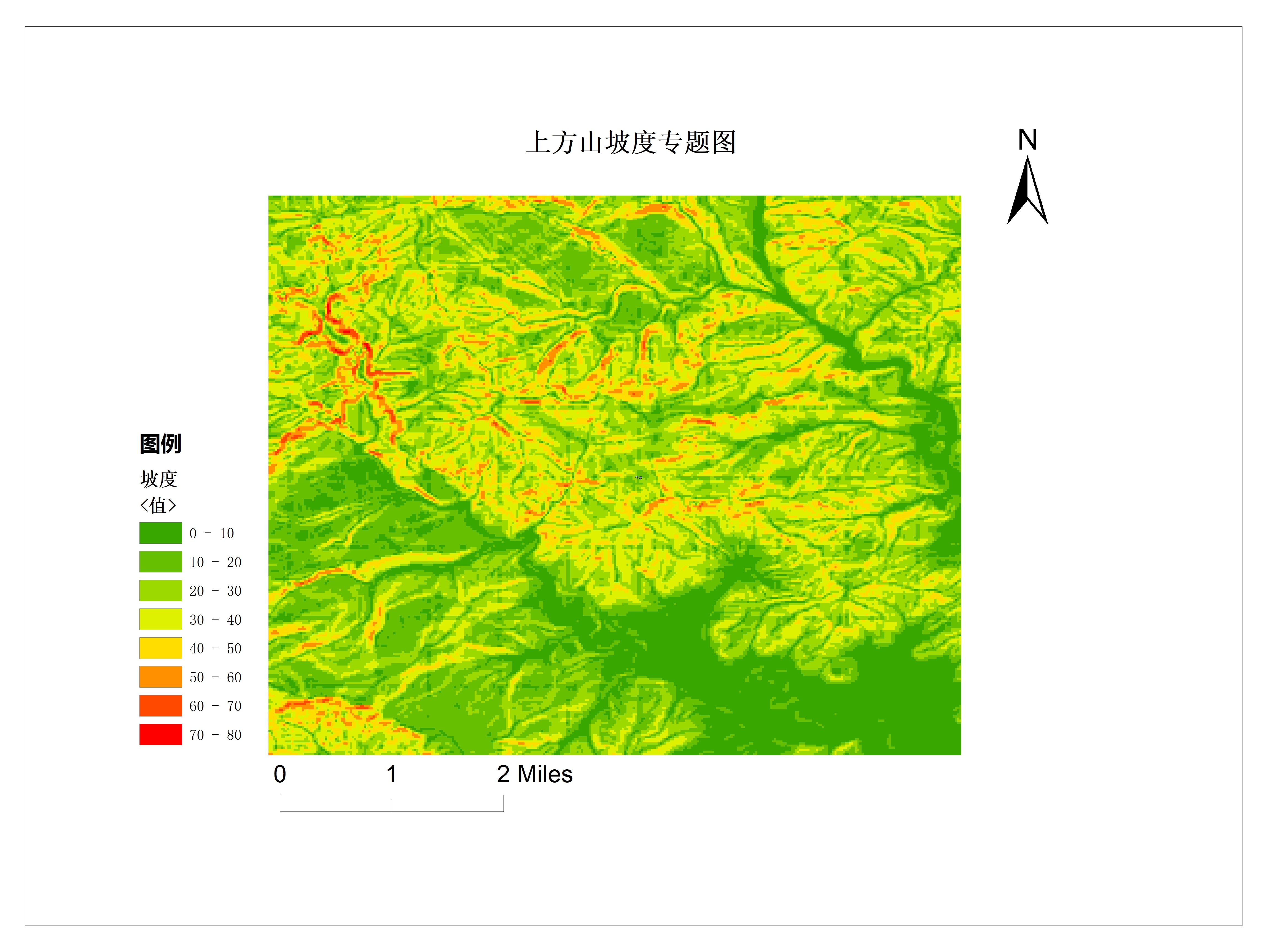
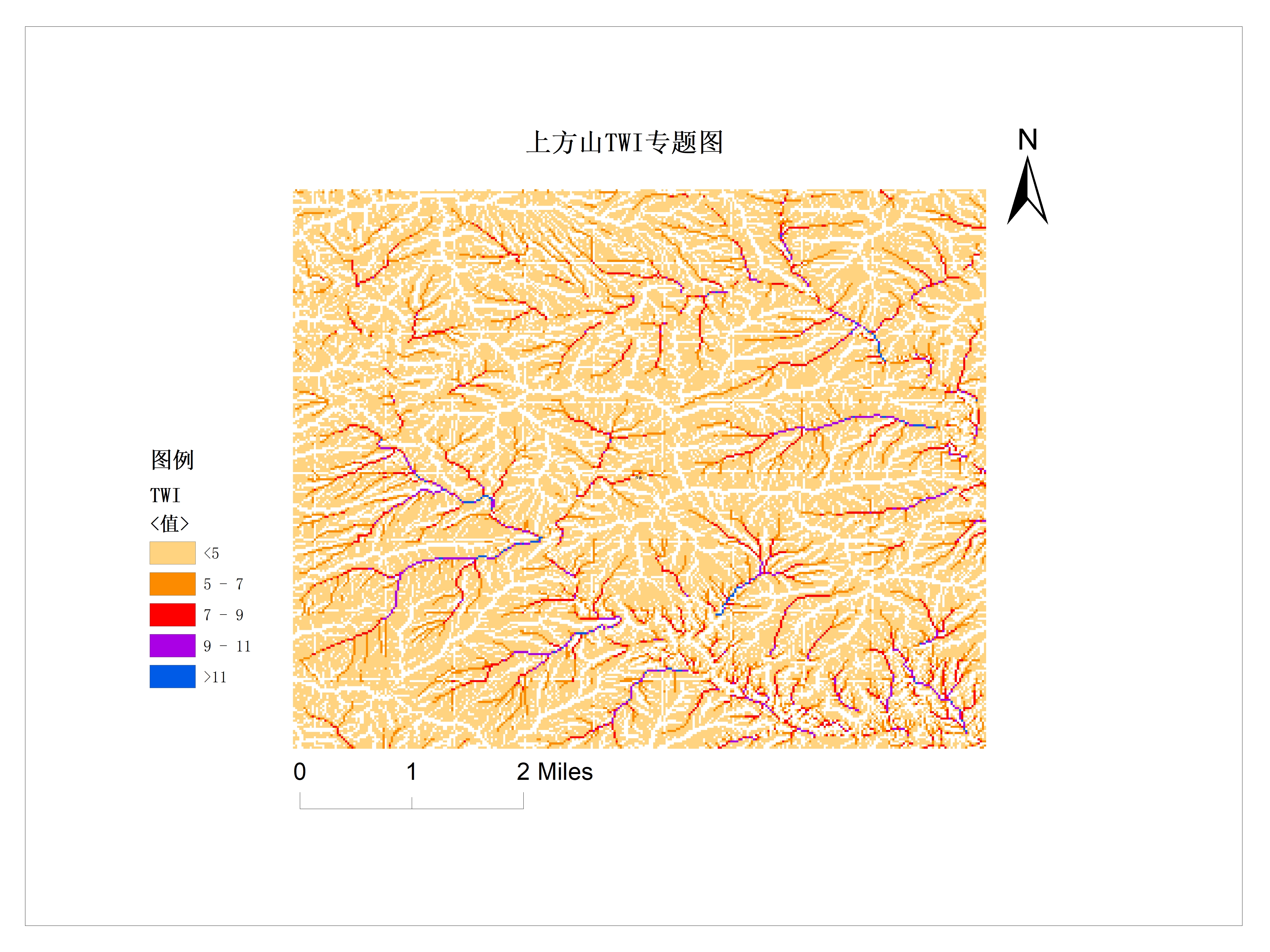
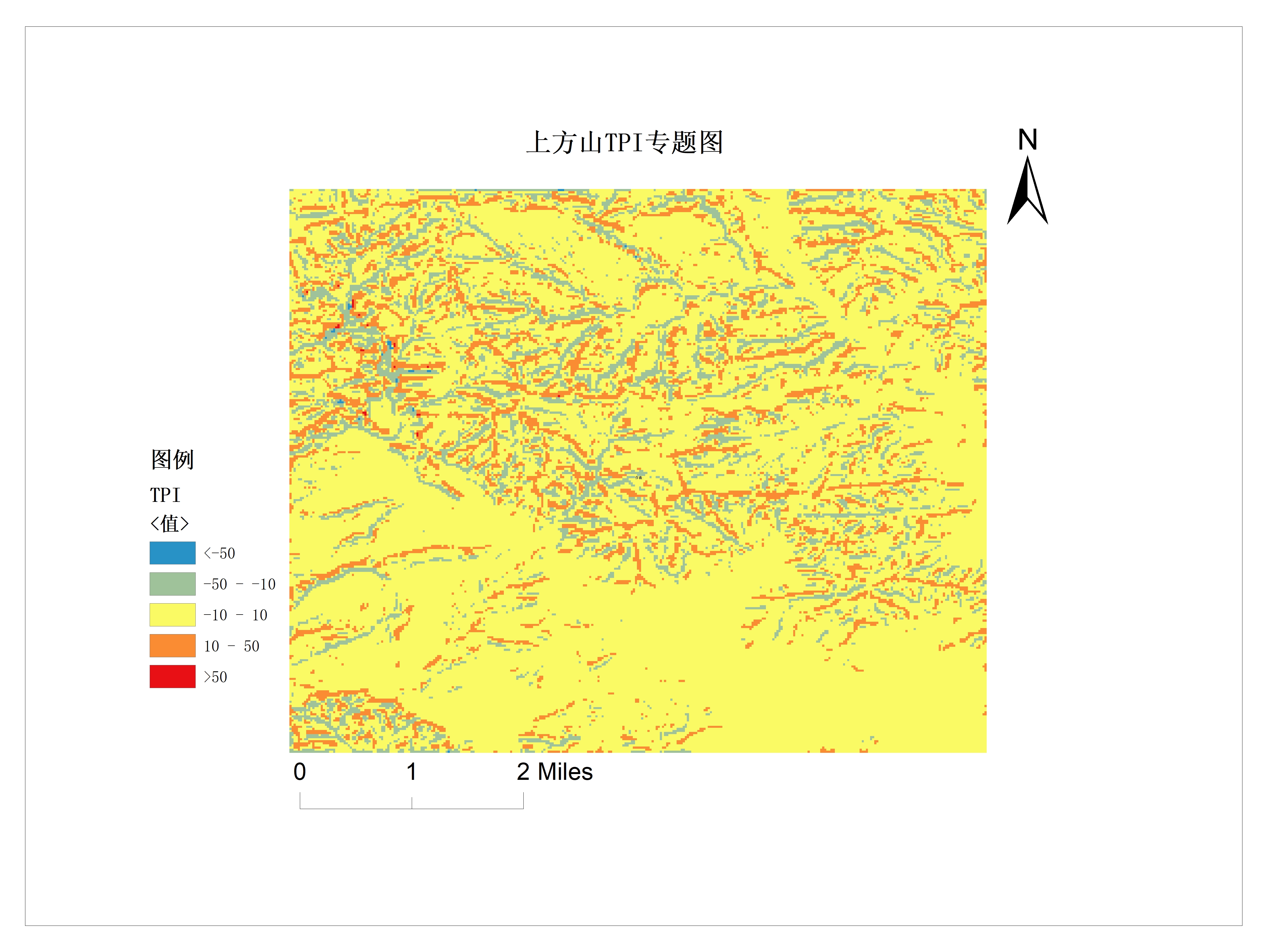
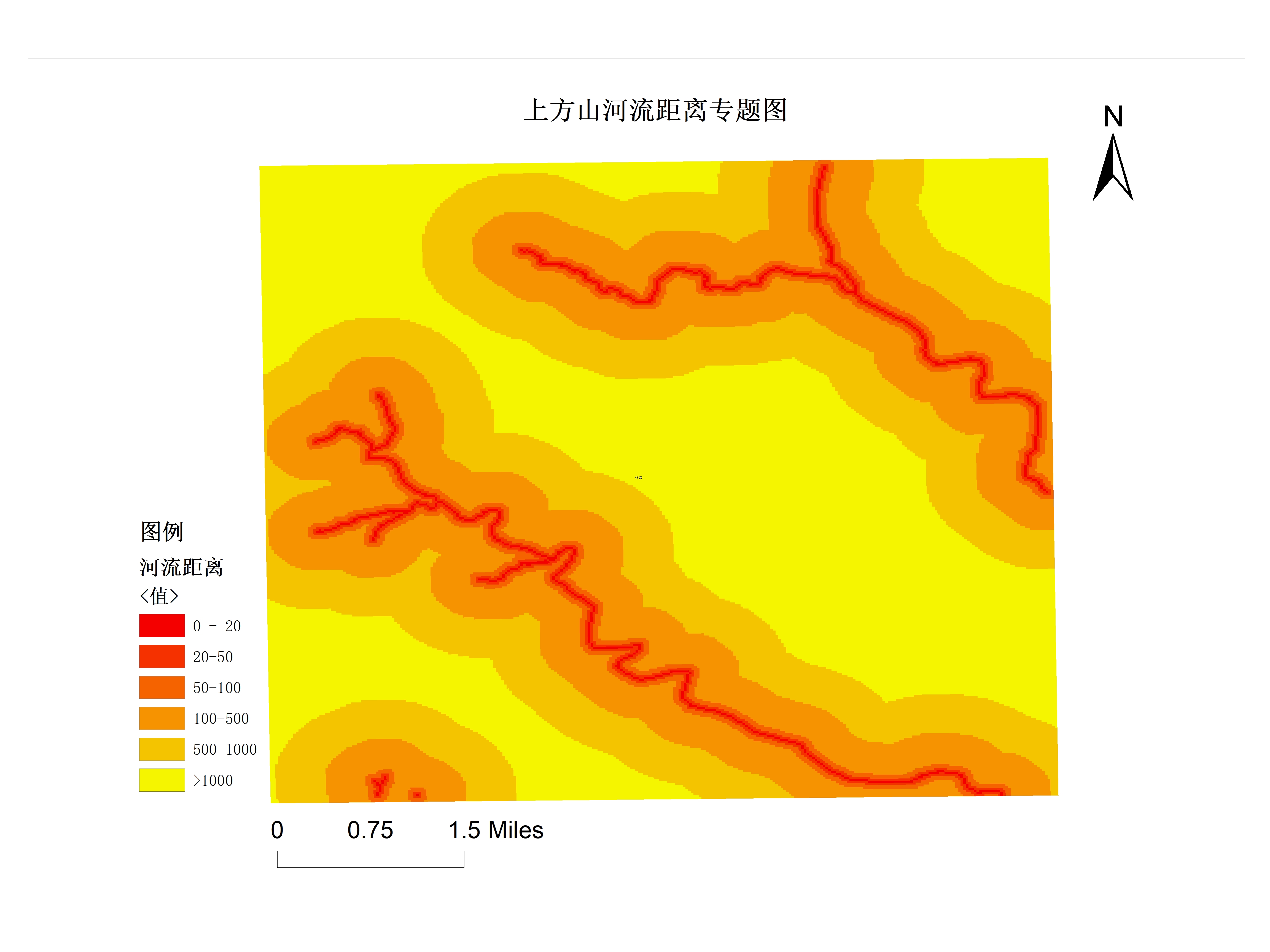
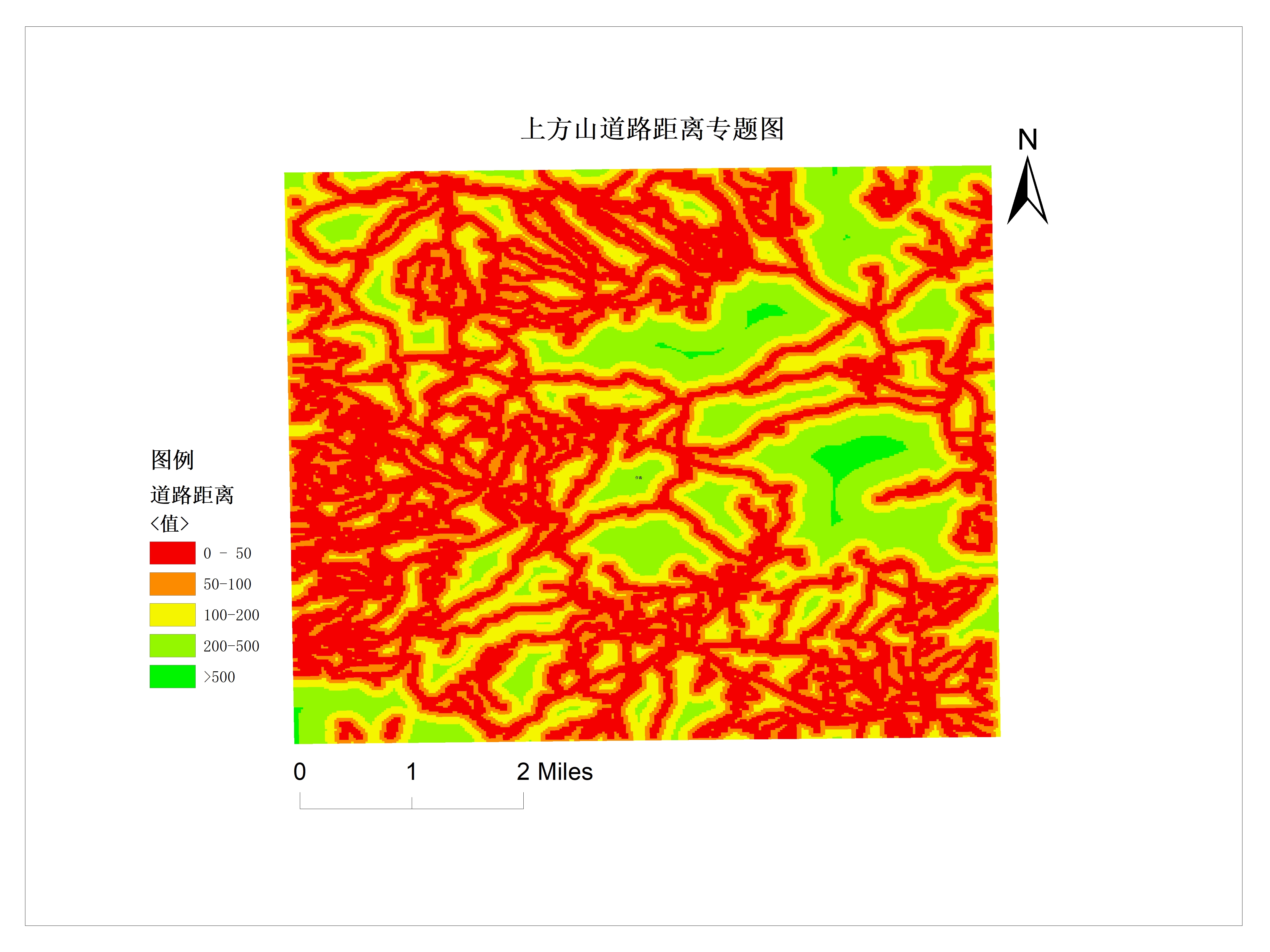
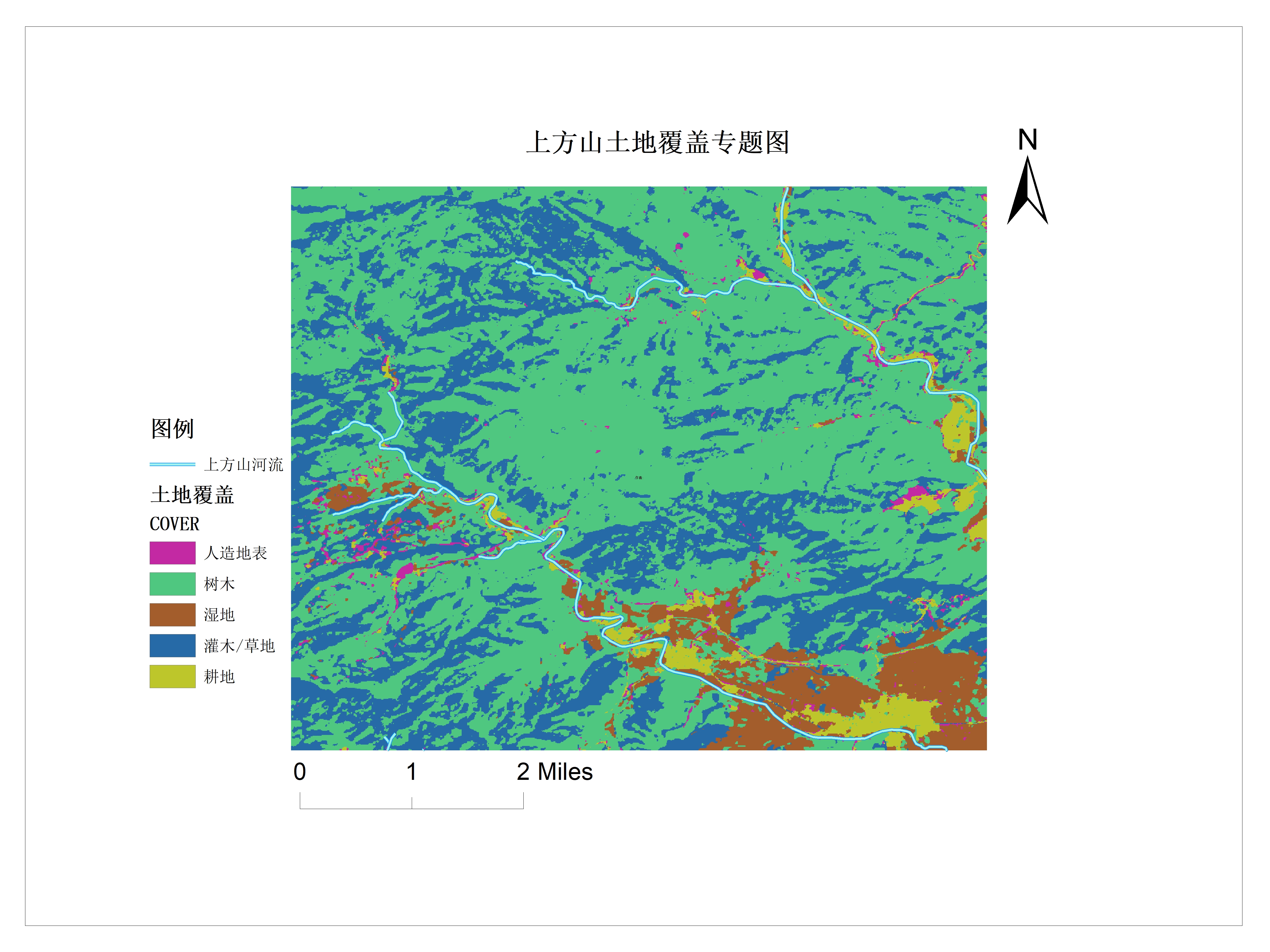
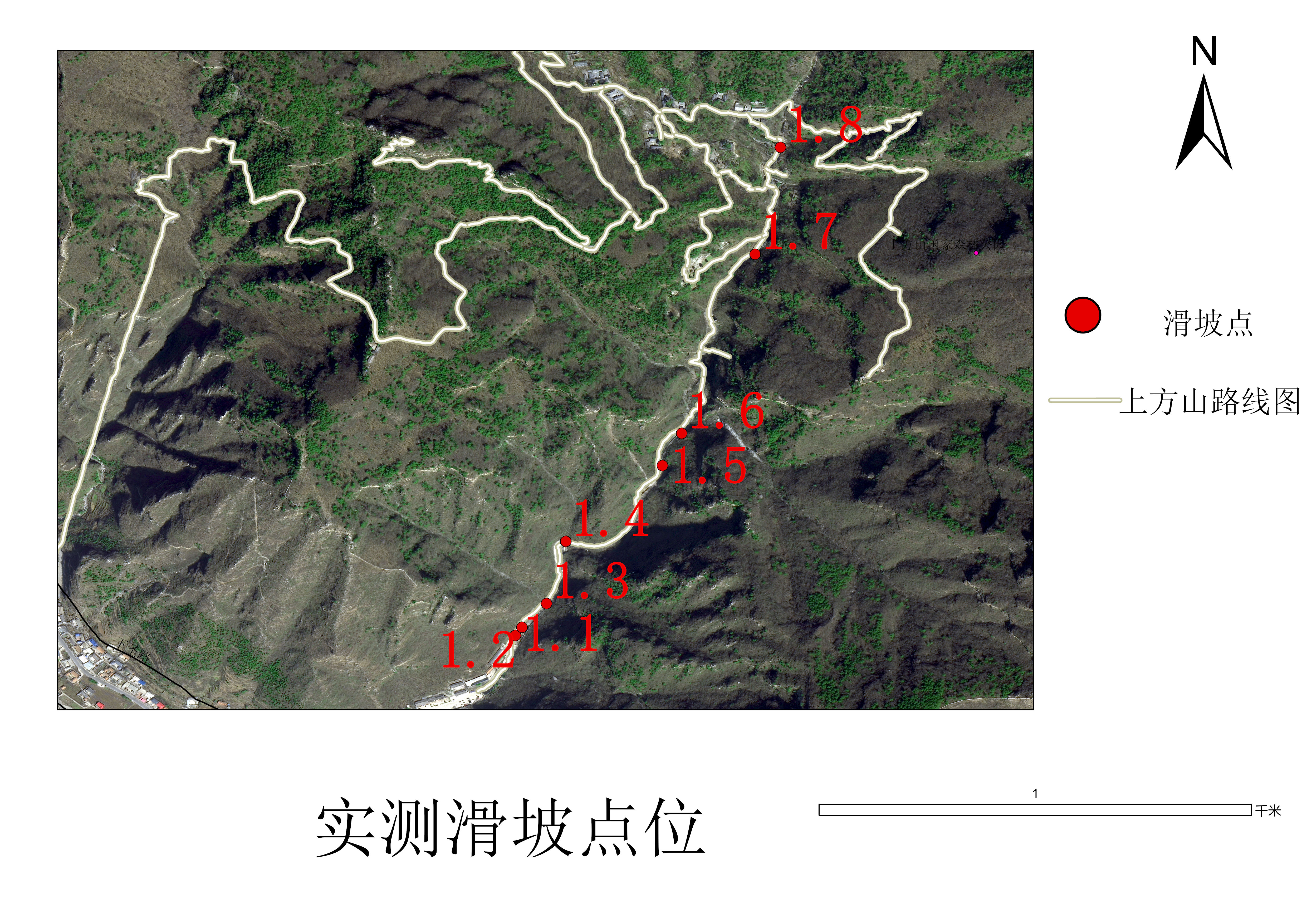
滑坡因子选择
选择滑坡敏感度因子,为滑坡易发性分级提供参考标准。
滑坡敏感度因子的选择原则:
1.有理论依据:基于滑坡形成机理;
2.可进行空间表达:因子能量化为空间图层
3.有代表性:可反映区域主要为滑坡触发机制。
- 地形因子:坡度坡向
- 地质因子:岩性、断层距离
- 水文因子:年均降水、极端降水
- 植被因子:NDVI、覆盖等级
- 人类因子:道路密度、工程扰动指数
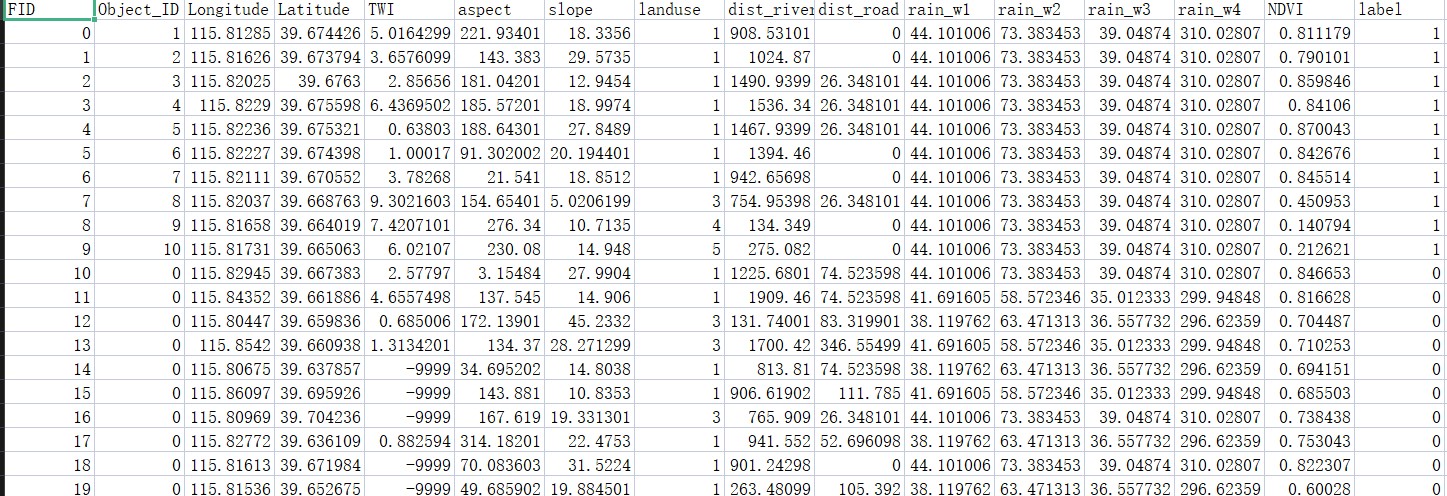
数据采集与预处理
研究需要收集上方山区域的地形数据、地质数据、气象数据植被数据以及人类活动数据等多源数据。通过GIS软件进行数据清洗、格式转换和空间配准,确保数据质量和一致性。
预处理步骤包括:数据归一化、缺失值处理、异常值检测等,为后续分析提供高质量的数据基础。
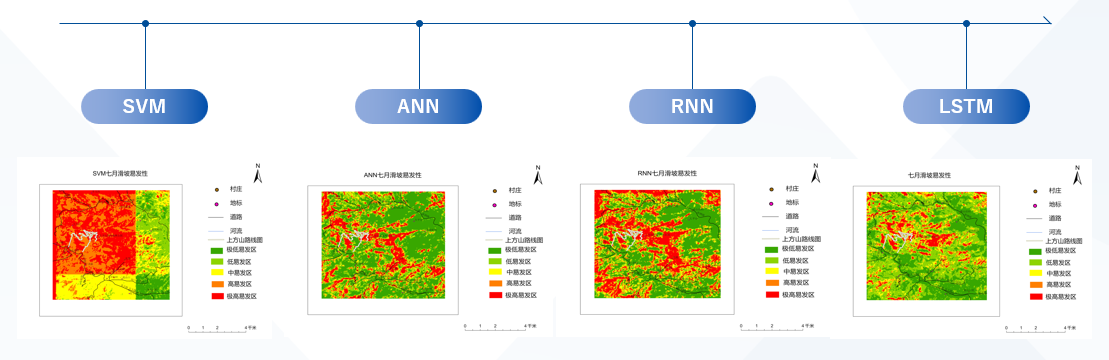
模型训练
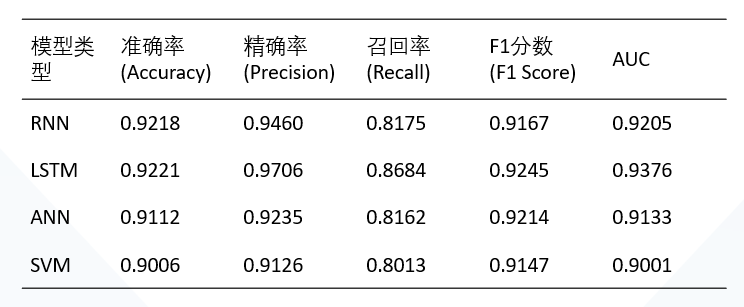
我们计划采用2种机器学习模型以及2种深度学习模型进行对比分析:
- 机器学习模型 —— 支持向量机SVM
- 机器学习模型 —— 人工学习网络ANN
- 深度学习模型 —— 循环神经网络RNN
- 深度学习模型 —— 长短期记忆网络LSTM
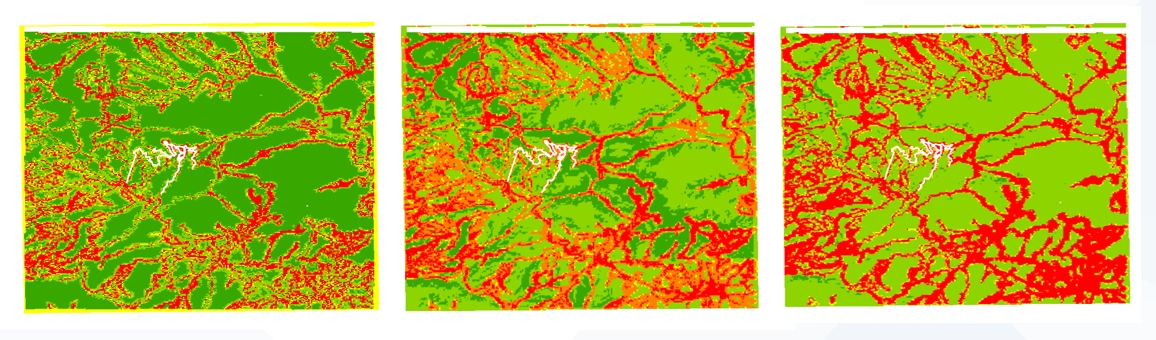
易发性图生成
基于模型预测结果,生成上方山区域的滑坡易发性图:
- 上方山汛期(7月)滑坡易发性图
- 不同降水量下上方山滑坡易发性图
- 在网页中可视化输出可交互查询的立体图像